



Augmenter la vitesse de chargement d’une page grâce à une cache de requêtes

Préambule
Une petite digression en introduction : oui, cache est bel et bien du genre féminin. A-t-on déjà entendu parler du cache de Ben Laden au Pakistan ou du cache d’armes de l’ETA qui a été découvert dans un maison du Sud-Ouest du France ? On utilise ce dépôt pour y cacher des données pour usage ultérieur.
Pour s’en souvenir, écrivez ceci sur une log, c’est à dire une bûche où graver des inscriptions. Parenthèse fermante.
Cadre de l’article
Cet article est un tutoriel technique adressé aux responsables et ingénieurs de production, ainsi qu’aux développeurs d’applications RESTful basées sur des requêtes SQL. Il décrit un paradigme qui pourrait permettre la diminution du temps de constitution d’un recordset (= jeu de données résultantes) lors d’une requête. Il est particulièrement adapté aux systèmes à forte inertie de données, c’est-à-dire dans lesquels les données changent peu souvent, et où les requêtes sont souvent identiques, en particulier en provenance de plusieurs clients simultanément. Il est particulièrement bien adapté aux CMS et aux systèmes basés sur des imports nocturnes quotidiens qui utiliseraient principalement ces données pendant la journée de travail qui suit.
QueryCache n’est qu’une brique du mur Qualité
La recherche de l’accélération de l’exécution des requêtes, ou plus précisément l’accélération de la constitution d’un recordset, n’a de sens que si elle s’inscrit dans le cadre plus large de la recherche de qualité pour votre application.
La Réactivité Utilisateur (UR en anglais) est une fonction de plusieurs variables. L’une de ces variables étant, je l’ai dit, la vitesse de traitement d’une requête. Elle-même fonction de l’optimisation de ladite requête, c’est à dire l’utilisation appropriée des index, et de la grammaire SQL, en profitant à fond de la factorisation, si applicable. Le principe de factorisation est de remplacer n requêtes WHERE primary_key = une_valeur_variable, par une unique requête qui s’appliquerait sur le jeu de toutes les valeurs possibles de“une_valeur_variable”. On passe ainsi de n requête à une seule. Evidemment cela s’accompagne d’un traitement en boucle par la suite.
Parmi les autres variables de la fonction performance, citons en particulier les performances du composant processeur, la capacité en mémoire vive, et donc l’aptitude à ne pas utiliser la mémoire cache, ou pire, la cache disque. On trouvera aussi parmi les facteurs d’UR, côté front-end cette fois, l’ergonomie, le traitement de composition de l’interface riche côté client autant que possible, l’utilisation de réseaux de fournisseurs de contenu (CDN) géographiquement proches de l’utilisateur final. Toutes ces variables sont à étudier puis à optimiser, afin que la qualité de l’expérience utilisateur (UX) globale s’en trouve améliorée.
Quelle différence avec la cache MySQL ?

A priori QueryCache est donc inadapté car il pourrait retourner des recordsets périmés. En réalité il est susceptible d’être mieux adapté, mais à des situations différentes du premier. En effet son fonctionnement n’est pas aléatoire mais complètement maîtrisé par le maître d’œuvre. Quelle que soit l’activité des autres utilisateurs, il sera forcément actif là où l’implémenteur le voudra. Tel un anticorps il agira qu’avec certaines requêtes SELECT et pas avec toutes, avec une durée de vie des données en cache maîtrisée. Il est particulièrement bien adapté aux systèmes où des données“un peu” périmées font tout à fait l’affaire. Ce point est très important : QueryCache ne testera pas la fraîcheur des données sources, c’est à dire dans les tables concernées par les requêtes en cache, mais uniquement la date d’expiration des jeux de données stockés dans cette cache. Veuillez donc utiliser QueryCache avec le plus grand arbitrage, selon l’inertie de vos données, les besoins de vos utilisateurs, et le compromis entre fraîcheur et performance (Orangina ?).
D’autre part cet article a un rôle pédagogique puisqu’il enseigne comment mettre en place une cache de données indexées par un hash. Ce système est bon à connaître car il s’apparente à un design pattern, même s’il ne figure pas tel quel dans la liste des design patterns bien connus établis par The Gang of Four.
QueryCache, un système de cache qui accélère l’exécution des requêtes SELECT ciblées

Si vous utilisez MySQL, vous pouvez vous aider de la notion de slow queries, et de leur journalisation possible par MySQL, pour établir une shortlist des candidats au“QueryCaching”. En bonus, vous trouverez ci-contre le schéma de principe d’un système qui prépare ce travail de shortlisting. A condition d’avoir un epsilon adapté, au bout que quelques heures ou journées de travail la cache devrait se remplir de textes SQL des requêtes ainsi "pêchées". Il ne vous reste plus qu’à implémenter au cas par cas QueryCache sur ces requêtes.
Dans mon framework maison, j’ai développé une couche d’abstraction à la bibliothèque standard php-mysql. A titre d’exemple, mysql_query est devenu db_query. Cette dernière fait appel à mysql_query après un certain nombre d’opérations de parsing, de logging, d’envoi d’email d’alerte si erreur, etc, bref, cette fonction est assez complexe, car au cœur du système d’assurance qualité et de continuité de service. Elle utilise en particulier en système de traçage des requêtes lentes plus fin que le système slow query natif. En vous inspirant de mon idée, vous pouvez mettre en place votre propre système, et en particulier ajouter à la cache QueryCache, en vue d’un traitement automatique ultérieur, toute requête lente de plus de epsilon secondes.
Pour inscrire une requête dans la cache avec son recordset, utilisez la méthode QueryCache::ExecuteAndStoreQuery.
Pour inscrire une requête dans la cache sans son recordset, ajoutez vous-même une méthode Store à QueryCache, en vous inspirant de ExecuteAndStoreQuery ! Ca vous fera un bon exercice tiens !
Schéma relationnel détaillé du fonctionnement du système
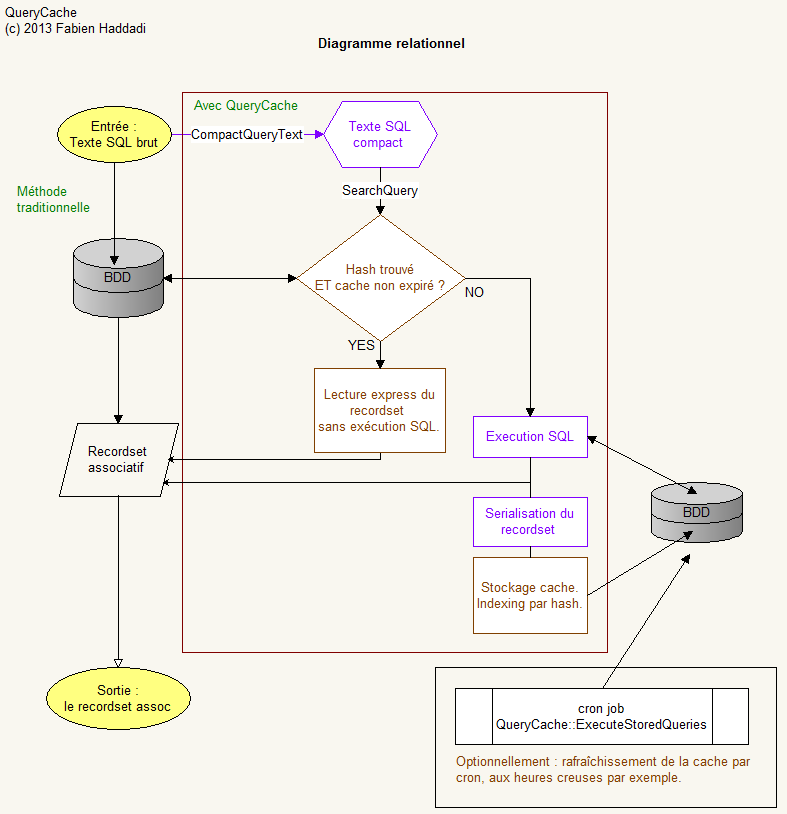
num_rows n’est pas utilisé à fin discriminatoire au sein de la classe, mais pourrait tout à fait l’être à des fins de présentation des données sur le front-end.
Implémentation de QueryCache en PHP
Techniquement, QueryCache pourrait être écrit dans n’importe quel langage. Puisque c’est ma spécialité, je l’ai écrit en PHP pour MySQL.
<?php
require "/path/to/my_standard_libs.inc"; // Ici vos inclusions standards
// Vous trouverez le package QueryCache en téléchargement en bas de cette article.
use Vendor\Tropicalm\Utils\QueryCache as QueryCache;
/*****************************************************************************/
// Exemple d'utilisation de l'API QueryCache
// Initialiser le chronomètre
$_t0 = microtime(true);
// Une grosse requête arrive...
$sql = file_get_contents("C:/Users/mylogin/QueryCacheTest/slow.sql");
/* Récupérer l'instance QueryCache (Singleton)
Notez l'utilisation du namespace Vendor\Tropicalm\Utils\QueryCache.
Si vous utilisez une version de PHP trop ancienne pour les namespaces,
passez-vous des préfixes QueryCache\
*/
$Query = QueryCache\QueryFactory::Create($sql, $lifetime = 900); // On lui donne 15' de durée de vie
$QueryCache = QueryCache\QueryCache::getInstance('mydatabasename');
// Fait-elle partie des requêtes cachées ?
// Si oui, récupérer son recordset directement dans la cache
if ($QueryCache->SearchQuery($Query)) {
/* FirePHP est mon implémentation personnelle de la classe FirePHP.
Elle loggue dans un fichier, ou en sortie standard, ou tout simplement en console FireBug.
Remplacez-la par un appel FirePHP standard, ou bien par echo, ou par n'importe quel logger de votre choix.
*/
FirePHP("Requête trouvée dans la cache. Dernière exécution le " . $Query->LastExecuted) .
". Expirera le " . date('d-m-Y H:i:s', strtotime($Query->LastExecuted) + $Query->ExpiresIn);
}
else {
FirePHP("Pas trouvé dans la cache, j'exécute la requête tout de suite pour la servir
et je la stocke avec une durée de vie de 600 secondes");
$QueryCache->ExecuteAndStoreQuery($Query, $lifetime = 600);
FirePHP(sprintf("Operation time %.3f s", microtime_float()-$_t0));
}
foreach($Query->Recordset as $index => $data) {
/*
Utilisez ici le tableau associatif $data dans votre code legacy,
tel que vous l'auriez écrit dans une boucle while($row = mysql_fetch_assoc($result)) {
// actions
}
*/
}
?>
Autre exemple : rafraîchissement des entrées de cache si une table source st modifiée
Supposons que la fraîcheur de votre cache n’est définie qu’à partir de la fraîcheur d’une autre table, appelée ici table source. Supposons que vous ayez utilisé votre application web depuis déjà quelques heures, et qu’un humain ou un processus modifie une donnée de la table source. Vous savez que votre cache est racie désormais. Enfin, supposons qu’il existe dans la cache plusieurs variantes de la même requêtes, selon que vous l’ayez invoquée via des ORDER BY particuliers par exemple. Idéalement il faudra rafraîchir automatiquement les entrées concernées, plutôt que d’attendre le rafraîchissement automatique, pas vrai ? La méthode intégrée QueryCache::RefreshStoredQueriesByRegExp() peut vous apporter une solution adéquate. Voyons ceci sur un exemple.
<?php
require "/path/to/my_standard_libs.inc";
// instruire d'utiliser le package QueryCache
use Vendor\Tropicalm\Utils\QueryCache as QueryCache;
// Soit l'élément déclencheur suivant :
$sql = "UPDATE `table_source` SET `quantite_recue` = 10 WHERE `sku` = 395822";
db_query($sql);
/**
Alors plusieurs entrées de la cache sont susceptibles d'avoir été màj.
Il vous suffit d'appeler la méthode suivante pour rafraîchir toutes les entrées concernées en une seule ligne,
et leur donner une journée de vie.
*/
$QueryCache->RefreshStoredQueriesByRegExp('^SELECT `table_source`\.\*');
/** Attention, l'expression régulière passée en argument doit correspondre au texte compacté de la requête effectivement utilisée dans votre code. */
?>
Implémentation sur le tiers métier
Sur le tiers métier, c’est un système à installer sur votre application à l’aide d’une classe à inclure à vos scripts PHP (téléchargement en bas de cette page) qui utiliseront le système. Une implémentation unitaire, au cas par cas, sur chaque requête candidate, sera ensuite facilement implémentée. Voyez l’exemple en téléchargement en fin d’article.Implémentation sur le tiers données
Sur le tiers données, il vous faudra ajouter une table dont le schéma est donné ci-dessous :Attention, la taille du champ query_hash doit correspondre à la longueur du hash d’après l’algorithme utilisé. Ici sha1.
CREATE TABLE IF NOT EXISTS `query_cache` (
`query_hash` char(40) NOT NULL,
`query_text_compact` text NOT NULL,
`recordset` mediumblob,
`num_rows` mediumint(8) unsigned DEFAULT NULL,
`creation_date` datetime NOT NULL,
`execution_date` datetime DEFAULT NULL,
`execution_time` decimal(6,3) unsigned DEFAULT NULL,
`expires_in` int(10) unsigned NOT NULL DEFAULT '21600',
`last_used_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`query_hash`),
KEY `last_used_date` (`last_used_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Téléchargement du package Vendor\Tropicalm\Utils\QueryCache
Utilisation, à décompresser et à placer sur le chemin de votre include_path.
dwnl://Vendor_Tropicalm_Utils_QueryCache.zip:Téléchargez QueryCache:
Cette classe en contient en fait trois : QueryFactory, Query et QueryCache.
QueryFactory fabrique des objets Query.
Query est un objet requête, à instancier autant de fois que vous voudrez.
QueryCache est l’objet unique du système de cache. Il se récupère en Singleton.
Crons de gestion
Voici un exemple de cron de refraîchissement des requêtes de la cache, précédée d’une purge des requêtes non-utilisées depuis plus d’une mois.
<?php
use Vendor\Tropicalm\Utils\QueryCache As QueryCache;
$QueryCache = QueryCache\QueryCache::getInstance('my_database_name');
$QueryCache->FlushOlderQueries(32); // 32 jours recommandés
$QueryCache->RefreshStoredQueries();
Améliorations réalisées post-scriptum
Depuis l’écriture initial de l’article, le temps a passé et le logiciel sur lequel j’ai implémenté cette cache l’a utilisée généreusement. La cache est devenue tellement populaire que certains recordsets stockés sont énormes, et ont donné lieu à une utilisation saturante de la mémoire dédiée aux scripts PHP. Je rappelle que cette dernière est définie par la directive memory_limit de php.ini, lisible par l’instruction PHP :
echo ini_get('memory_limit');
Afin d’éviter le piège de donner à tout script PHP du serveur une quantité large de mémoire de façon à "être tranquille", je préfère ajouter une intelligence de réallocation de mémoire à l’intérieur de la boucle de constitution du recordset. A la mode du bon vieux realloc C, voici le patch que je propose, et qui donne en ce moment satisfaction sur le serveur que je supervise :
Dans la méthode Execute, remplacez
<?php
[...]
while($_row = db_fetch_assoc($_result)) {
$this->Recordset []= $_row;
}
[...]
?>
par
<?php
[...]
while($_row = db_fetch_assoc($_result)) {
$this->Recordset []= $_row;
/* In case memory gets exhausted (memory_limit - REALLOC_INCREMENT lignes), reallocate some. */
ReallocArithmeticIfExhaustion(self::REALLOC_INCREMENT*strlen(implode('', $_row)));
}
[...]
?>
Voici l’implémentation de la fonction utilitaire ReallocArithmeticIfExhaustion ; je l’ai placée dans une bibliothèque commune au projet.
<?php
[...]
// Add $Incr bytes to current memory allocation in an arithmetic series (vs geometric series) if the current memory usage is exceeds limit - $Incr
function ReallocArithmeticIfExhaustion($Incr = 1048576) {
$MemoryLimit = IniGetMemoryLimitInt();
// printf("ReallocArithmeticIfExhaustion($Incr) : current memory_limit=%dB, base usage=%d kB\n", $MemoryLimit, memory_get_usage() / 1024);
if (memory_get_usage() > $MemoryLimit - $Incr) {
printf("Attempting to realloc up to %f MB...", ($MemoryLimit + $Incr) / 1024 / 1024);
if (ini_set('memory_limit', $MemoryLimit + $Incr)) {
$MemoryLimit *= 2;
// print "SUCCESS.\n";
return true;
}
else {
// print "FAILED.\n";
return false;
}
}
else {
// print "It's ok, we've got some room left.\n";
}
return 0;
}
[...]
?>
Améliorations possibles
Ajouter une méthode qui ne fait qu’écrire le texte des requêtes vues passer dans votre wrapper à la base de données, mais sans déclencher leur exécution dans un premier temps. Le champ execution_time est à renseigner. Après quelques jours d’utilisation on pourra détecter, en classant par execution_time décroissante, les requêtes sur lesquelles mettre le projecteur.